Research
Interactive Multilayer Gaussian Garments for Low-Cost Try-On
- Zesch, R., Shen, I., Xie, H., Zhu, B., Sueda, S. & Igarashi, T., Graphics Interface, 2025
- 🏆 Best Graphics Paper Award
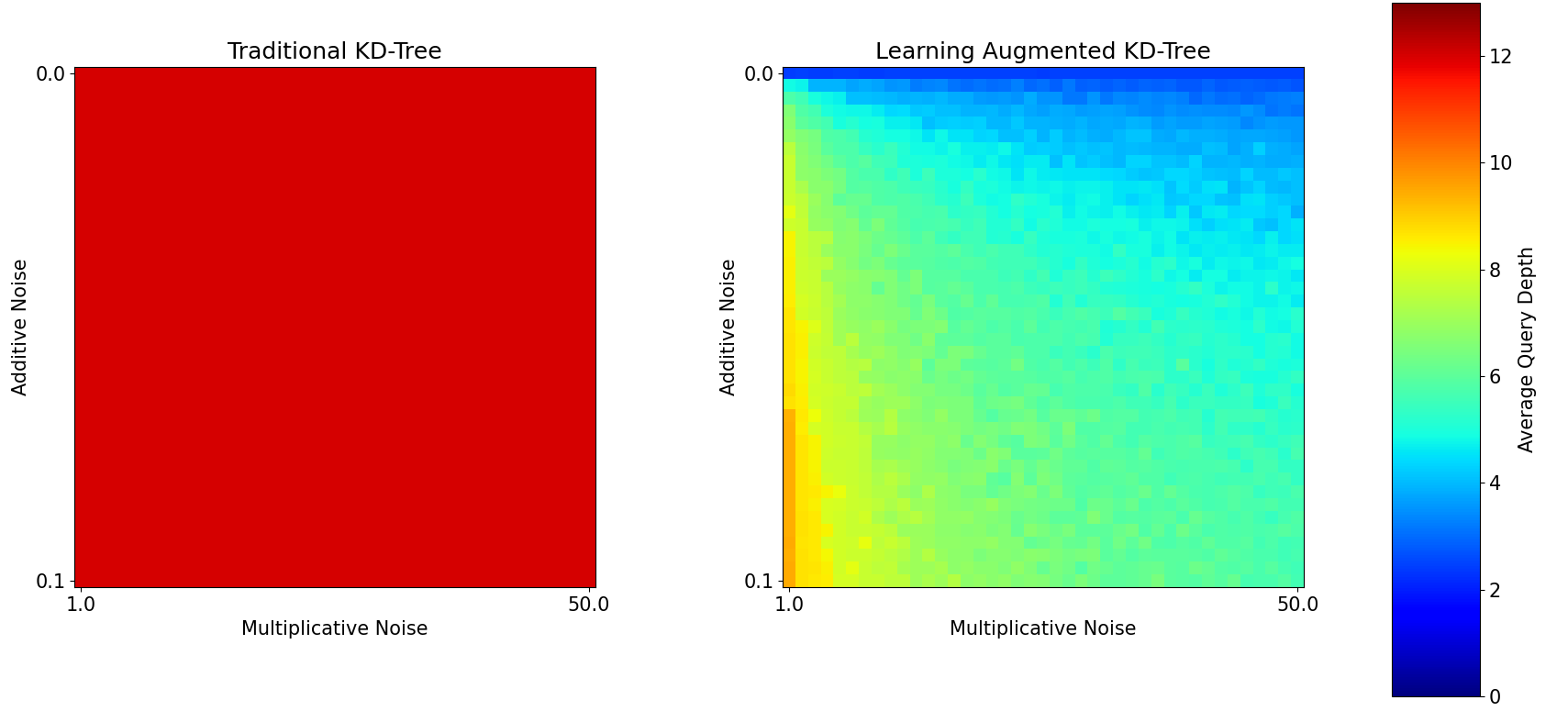
Learning-Augmented Search Data Structures
- Zesch, R.*, Fu, C.*, Nguyen, B.*, Seo, J.*, Zhou, S., ICLR, 2025
NBD-Tree: Neural Bounded Deformation Tree for Collision Culling of Deformable Objects
- Zesch, R., Witemeyer, B., Xiong, Z., Levin, D. & Sueda, S., Southwest Data Science Conference, 2023
- 🏆 Best Paper Award
Neural Collision Detection for Deformable Objects
- Zesch, R., Witemeyer, B., Xiong, Z., Levin, D. & Sueda, S., arXiv:2202.02309, 2022